

SQL Window Functions
SQL window functions are powerful tools for executing complex calculations and analytics on data sets. They allow you to work with data in a way that goes beyond the traditional aggregate functions such as SUM, COUNT, and AVG. This article will introduce you to SQL window functions, explain their basic syntax, and cover some of the most common and helpful window functions.
A window function is a type of SQL function that performs a calculation across a set of rows related to the current row. This set of rows is called a “window”. The window can be defined in many ways, such as by specifying a range of rows or grouping rows based on a common attribute. For example, you might use a window function to calculate the running total of sales for each product or rank customers based on their purchase history.
Most common window functions:
- Ranking Functions
- Aggregate Functions
- Analytic Functions
Basic Windowing Syntax
To use a window function, you must first define the window on which the function will operate. The OVER() clause specifies the partition and order of the window. Here is an example of the basic windowing syntax:
SELECT
column1
, column2
, SUM(column3) OVER (PARTITION BY column1 ORDER BY column2) as running_total
FROM
mytable;In this example, we are using the SUM window function to calculate the running total of column3 for each value of column1. An ORDER BY clause specifies that the rows should be processed in order of column2, and the PARTITION BY clause groups the rows based on their value in column1.
Ranking Functions
These functions assign a rank or row number to each row based on specific criteria or ordering. Examples of ranking functions include ROW_NUMBER(), RANK(), and DENSE_RANK().
ROW_NUMBER()
SELECT
column1
, column2
, column3
, ROW_NUMBER() OVER (ORDER BY column3 DESC) as row_number
FROM
mytable;In this example, we are using the ROW_NUMBER() function to assign a unique number to each row based on its value in column3. After running this query to the bookshop_sales table, we would get the following result:
SELECT
book_id
, month_sales
, sales
, ROW_NUMBER() OVER (ORDER BY sales DESC) as row_number
FROM
bookshop_sales;
RANK() and DENSE_RANK()
These functions rank each row based on its value in a specified column. The only difference is that the RANK() assigns the same rank to rows with the same value, while the DENSE_RANK() assigns consecutive ranks to rows with the same value.
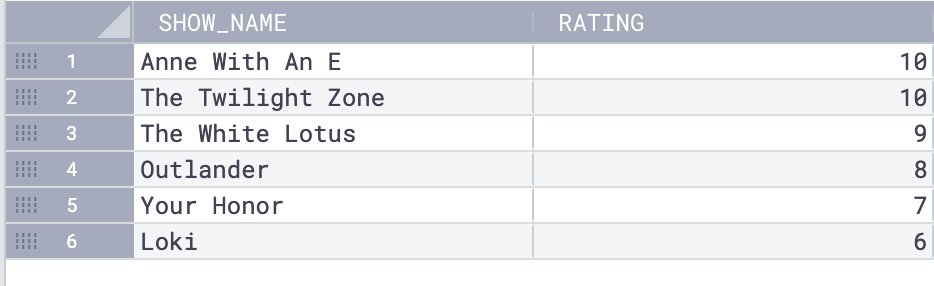
Consider the ratings in the following tv_show table:
![]()
You can use this basic RANK() syntax to assign a unique rank to each distinct value:
SELECT
Column1
, Column2
, RANK() OVER (ORDER BY Column2 DESC) as Rank
FROM
table;Here’s how it looks:
SELECT
show_name
, rating
, RANK() OVER (ORDER BY rating DESC) as Rank
FROM
tv_show;
‘Anne With an E’ and ‘The Twilight Zone’ both have a ‘1’ rating and are assigned the same rank of ‘1’. The next available rank is ‘2’, but it is skipped because there are two rows with ‘1’.
On the other hand, the DENSE_RANK() gives a unique position to each distinct value in the result set, but it does not skip any levels if two or more rows have the same value.
Here is the basic syntax:
SELECT
Column1
, Column2
, DENSE_RANK() OVER (ORDER BY Column2 DESC) as Dense_Rank
FROM
table;In the following result set, ‘Anne With an E’ and ‘The Twilight Zone’ both have a rating of ‘10’ and are assigned the same rank of ‘1’. The next available rank is ‘2’, assigned to The White Lotus. Outlander is assigned rank 3.
SELECT
show_name
, rating
, DENSE_RANK() OVER (ORDER BY rating DESC) as Dense_Rank
FROM
tv_show;
Aggregate Functions
These functions perform calculations across a group of rows in a result set, such as calculating a column’s sum, average, minimum, or maximum value.
Suppose you need to calculate the total sales for each month and book and a running total for each book. Here’s your table:
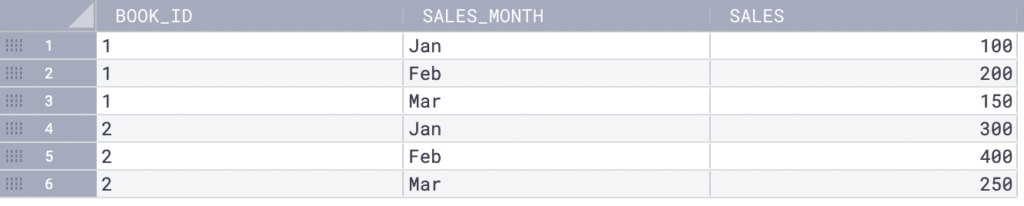
SELECT
book_id
, month_sales
, sales
, SUM(sales) OVER (PARTITION BY book_id ORDER BY month_sales) AS running_total
, SUM(sales) OVER (PARTITION BY month_sales) AS monthly_total
FROM bookshop_sales;
With the OVER clause, you can use SUM as a window function. Then, use the PARTITION BY clause to partition the result set by book_id order by month_sales.
The first window function calculates the total sales for each book using the SUM() function and displays the result in the running_total column. The second window function calculates the total sales for each month using the SUM() function. The result is in a column named monthly_total.
The result has the running total of sales for each book and the total sales for each month.

Analytic Functions
These functions perform calculations on a range of rows in a result set relative to the current row. They are often used to perform complex calculations or statistical analysis of data. Analytic functions include LEAD(), LAG(), NTILE(), and FIRST_VALUE().
LAG() and LEAD()
SQL’s LAG() function is used to access the previous row in the result set, while the LEAD() function accesses the next row in the result set. Both functions are part of SQL window functions and compare the current row with its neighboring rows.
Consider the following table named bookshop_sales:
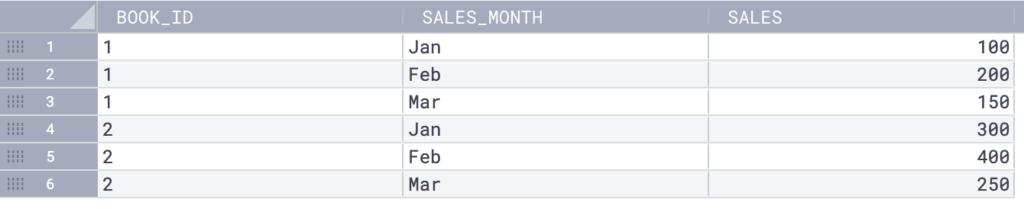
Here is an example of using LAG() to compare the current row with the previous row in the result set:
SELECT
book_id
, month_sales
, sales
, LAG(sales) OVER (PARTITION BY book_id ORDER BY month_sales) as Prev_Sales
FROM
bookshop_sales;This query will produce the following result set:

The LAG() function returns the sales from the previous row for each book_id, based on the order of the month_sales column. The first row for each product has a NULL value because there is no previous row.
SELECT
book_id
, month_sales
, sales
, LAG(sales) OVER (PARTITION BY book_id ORDER BY month_sales) as Prev_Sales
FROM
bookshop_sales;This query will produce the following result set:

The LEAD() function returns the sales from the next row for each book_id based on the order of the month_sales column. The last row for each product has a NULL value because there is no next row.
NTILE()
The NTILE() function in SQL divides a result set into a specified number of groups, or “tiles”, with each group having an equal number of rows as far as possible.
To understand the NTILE() in SQL, consider the following table:
You can use the NTILE() statement to divide the result set into 3 equal groups using the following statement:
SELECT
Column1
, Column2
, NTILE(4) OVER (ORDER BY Column2 DESC) as Tercile
FROM
table_name;After running this query, you get a result set into a specified number of groups, or “tiles”, with each group having an equal number of rows as far as possible.

In this example, the tercile number ranges from 1 to 3, with 1 being the highest and 3 being the lowest. The tercile numbers are assigned based on the rating column in descending order.
You can adjust the number of tiles by changing the argument of the NTILE() function. For example, if you want to divide the result set into 4 equal groups, you can replace NTILE(3) with NTILE(4) in the query above.
FIRST_VALUE()
The FIRST_VALUE() function is an analytic SQL window function that returns the value of the first row in a window frame. Here’s an example of how it works:
Suppose you have a table named bookshop_sales with columns for book_id, month_sales, and sales.
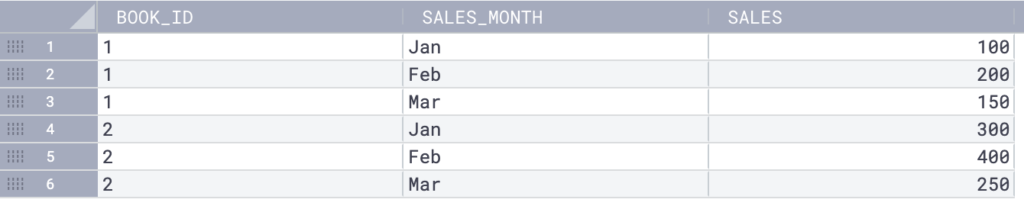
Here’s an example of calculating the value of the first sale for each book in each month:
SELECT
book_id
, month_sales
, sales
, FIRST_VALUE(Sales) OVER (PARTITION BY book_id, month_sales ORDER BY sales) AS first_sales
FROM
bookshop_sales;
In this query, we’re selecting the book_id, month_sales, and sales columns from the bookshop_sales table, along with a new column named first_sales that uses the FIRST_VALUE() function as a window function.

In this result set, the first_sales column shows the value of the first sale for each book in each month. For example, the first sale for book_id 1 in January was 100, so the first_sales value is 100 for both rows where book_id 1 and January appear in the table.

